This is the multi-page printable view of this section. Click here to print.
Blog
Information on Parquet Features
Variant Type in Apache Parquet for Semi-Structured Data
The Apache Parquet community is excited to announce the addition of the Variant type—a feature that brings native support for semi-structured data to Parquet, significantly improving efficiency compared to less efficient formats such as JSON. This marks a significant addition to Parquet, demonstrating how the format continues to evolve to meet modern data engineering needs.
While Apache Parquet has long been the standard for structured data where each value has a fixed and known type, handling heterogeneous, nested data often required a compromise: either store it as a costly-to-parse JSON string or flatten it into a rigid schema. The introduction of the Variant logical type provides a native, high-performance solution for semi-structured data that is already seeing rapid uptake across the ecosystem.
What is Variant?
Variant is a self-describing data type designed to efficiently store and process semi-structured data—JSON-like documents with arbitrary and evolving schemas.
Why Variant?
Consider a common scenario: storing logged event data that might evolve as new events are added, or fields are added or removed from specific event types. For example, you might have events like:
{"timestamp": "2026-01-15T10:30:00Z", "user": 5, "event": "login"}
{"timestamp": "2026-01-15T11:45:00Z", "user": 5, "event": "purchase", "amount": 99.99}
{"timestamp": "2026-01-15T12:00:00Z", "user": 7, "event": "login", "device": "mobile"}
Traditional approaches that store JSON as text strings require full parsing to access any field, making queries slow and resource-intensive. Variant solves this by storing data in a structured binary format that enables direct field access through offset-based navigation. Query engines can jump directly to nested fields without deserializing the entire document, dramatically improving performance.
Binary encodings like BSON improve upon plain JSON by storing data in binary format, but they still redundantly store field names like "timestamp", "user", and "event" in every row, wasting storage space. Variant is optimized for the common case where multiple values share a similar structure: it avoids redundantly storing repeated field names and standardizes the best practice of “shredded storage” for pre-extracting structured subsets.
Key Benefits
Type-Preserving Storage: Original data types are maintained in their native formats—data types (integers, strings, booleans, timestamps, etc.) are preserved, unlike JSON which has a limited type system with no native support for types like timestamps or integers.
Efficient Encoding: The binary format uses field name deduplication to minimize storage overhead compared to JSON strings or BSON encoding.
Fast Query Performance: Direct offset-based field access provides performance improvements over JSON string parsing. Optional shredding of frequently accessed fields into typed columns further enhances query pruning and predicate pushdown.
Schema Flexibility: No predefined schema is required, allowing documents with different structures to coexist in the same column. This enables seamless schema evolution while maintaining full queryability across all schema variations, while still taking advantage of common structures when present.
Overview of Variant Type in Parquet
Parquet introduced the Variant logical type in August 2025.
Variant Encoding
In Parquet, Variant is represented as a logical type and stored physically as a struct with two binary fields. The encoding is designed so engines can efficiently navigate nested structures and extract only the fields they need, rather than parsing the entire binary blob.
optional group event_data (VARIANT(1)) {
required binary metadata;
required binary value;
}
metadata: Encodes type information and shared dictionaries (for example, field-name dictionaries for objects). This avoids repeatedly storing the same strings and enables efficient navigation.value: Encodes the actual data in a compact binary form, supporting primitive values as well as arrays and objects.
Example
A web access event can be stored in a single Variant column while preserving the original data types:
{
"userId": 12345,
"events": [
{"eType": "login", "timestamp": "2026-01-15T10:30:00Z"},
{"eType": "purchase", "timestamp": "2026-01-15T11:45:00Z", "amount": 99.99}
]
}
Compared with storing the same payload as a JSON string, Variant retains type information (for example, timestamp values are stored as integers rather than being stored as strings), which improves correctness, enables more efficient querying and requires fewer bytes to store.
Just as importantly, Variant supports schema variability: records with different shapes can coexist in the same column without requiring schema migrations. For example, the following record can be stored alongside the event record above:
{
"userId": 12345,
"error": "auth_failure"
}
Shredding Encoding
To enhance query performance and storage efficiency, Variant data can be shredded by extracting frequently accessed fields into separate, strongly-typed columns, as described in the detailed shredding specification. For each shredded field:
- If the field matches the expected schema, its value is written to the strongly typed field.
- If the field does not match, the original representation is written as a Variant-encoded binary field and the corresponding strongly typed field is left NULL.

The Parquet writer, typically a query engine, decides which fields to shred based on access patterns and workload characteristics. Once shredded, the standard Parquet columnar optimizations (encoding, compression, statistics) are used for the typed columns.
Implementation Considerations
Schema Inference: Engines can infer the shredding schema from sample data by selecting the most frequently occurring type for each field. For example, if
event.idis predominantly an integer, the engine shreds it to an INT64 column.Type Promotion: To maximize shredding coverage, engines can promote types within the same type family. For example, if integer values vary in size (INT8, INT32, INT64), selecting INT64 as the shredded type ensures all integer values can be shredded rather than falling back to the unshredded representation.
Metadata Control: To control metadata overhead, engines may limit the number of shredded fields, since each field contributes statistics (min/max values, null counts) to the file footer and column stats.
Explicit Shredding Schema: When read patterns are known in advance, engines can specify an explicit shredding schema at write time, ensuring that frequently accessed fields are shredded for optimal query performance.
Performance Characteristics
Selective field access: When queries access only the shredded fields, only those columns are read from Parquet, skipping the rest, benefiting from column pruning and predicate pushdown.
Full Variant reconstruction: When queries require access to the complete Variant object, there is a performance overhead as the engine must reconstruct the Variant by merging data from the shredded typed fields and the base Variant column.
Examples of Shredded Parquet Schemas
The following example shows shredding non-nested Variant values. In this case, the writer chose to shred string values as the typed_value column. Rows that do not contain strings are stored in the value column with binary Variant encoding.
optional group SIMPLE_DATA (VARIANT(1)) = 1 {
required binary metadata; # variant metadata
optional binary value; # non-shredded value
optional binary typed_value (STRING); # the shredded value
}
The series of variant values "Jim", 100, {"name": "Jim"} are encoded as:
| Variant Value | value | typed_value |
|---|---|---|
"Jim" | null | "Jim" |
100 | 100 | null |
{"name": "Jim"} | {"name": "Jim"} | null |
Shredding nested Variant values is similar, with shredding applied recursively, as shown in the following example. In this case, the userId field is shredded as an integer and stored in two columns: typed_value.userId.typed_value when the value is an integer, and typed_value.userId.value otherwise. Similarly, the eType field is shredded as a string and stored in typed_value.eType.typed_value and typed_value.eType.value.
optional group EVENT_DATA (VARIANT(1)) = 1 {
required binary metadata; # variant metadata
optional binary value; # non-shredded value
optional group typed_value {
required group userId { # userId field
optional binary value; # non-shredded value
optional int32 typed_value; # the shredded value
}
required group eType { # eType field
optional binary value; # non-shredded value
optional binary typed_value (STRING); # the shredded value
}
}
}
The table below illustrates how the data is stored:
| Variant Value | value | typed_value.userId.value | typed_value.userId.typed_value | typed_value.eType.value | typed_value.eType.typed_value |
|---|---|---|---|---|---|
{"userId": 100, "eType": "login"} | null | null | 100 | null | "login" |
100 | 100 | null | null | null | null |
{"userId": "Jim"} | null | "Jim" | null | null | null |
{"userId": 200, "amount": 99} | {"amount": 99} | null | 200 | null | null |
Ecosystem Adoption: A Success Story
One of the most remarkable aspects of Variant’s addition to Parquet is the rapid and widespread ecosystem adoption, demonstrating the strength of collaboration within the Apache Parquet community.
Variant support has been implemented across multiple Parquet libraries including Java, Rust, and Go. For the most current implementation status across all languages and platforms, refer to the official Parquet implementation status page.
Major query engines have also integrated Variant support, including DuckDB, Apache Spark, and Snowflake. This cross-ecosystem adoption highlights both the value of the Variant type and the Parquet community’s commitment to evolving the format to meet modern data challenges.
Real-World Examples
This section illustrates how users can interact with Variant using Apache Spark 4.0
Event Stream Analytics
Event streaming applications often handle events with evolving schemas, where different event types contain varying fields. Variant provides a flexible solution for storing heterogeneous event data without requiring schema migrations.
Example: User Activity Events
-- Create table with Variant column
CREATE TABLE event_stream (
event_id INTEGER,
event_data VARIANT
);
-- Insert events with different schemas
INSERT INTO event_stream VALUES
(1, PARSE_JSON('{"user": {"id": 100, "country": "US"}, "actions": ["login", "view_dashboard"]}')),
(2, PARSE_JSON('{"user": {"id": 101, "country": "UK", "premium": true}, "actions": ["login", "upgrade"]}')),
(3, PARSE_JSON('{"user": {"id": 102, "country": "CA"}, "session_duration": 3600}'));
-- Query events with path notation - handles different schemas gracefully
SELECT
event_id,
event_data:user.id::INTEGER as user_id,
event_data:user.country::STRING as country,
event_data:user.premium::BOOLEAN as is_premium
FROM event_stream;
IoT Sensor Data
IoT deployments often involve diverse sensor types, each producing data with unique structures. Traditional approaches require either separate tables per sensor type or complex union schemas, or inefficient JSON / BSON encoding. Variant enables unified storage while maintaining type safety.
Example: Multi-Sensor Data Pipeline
-- Create unified sensor table
CREATE TABLE sensor_readings (
reading_id INTEGER,
timestamp TIMESTAMP,
sensor_data VARIANT
);
-- Insert data from different sensor types
INSERT INTO sensor_readings VALUES
(1, '2026-01-28 10:00:00'::timestamp,
PARSE_JSON('{"sensor_id": "T001", "temp": 72.5, "unit": "F", "battery": 95}')),
(2, '2026-01-28 10:00:05'::timestamp,
PARSE_JSON('{"sensor_id": "M001", "motion_detected": true, "confidence": 0.95, "zone": "entrance"}')),
(3, '2026-01-28 10:00:10'::timestamp,
PARSE_JSON('{"sensor_id": "C001", "image_url": "s3://bucket/img_001.jpg", "objects_detected": ["person", "vehicle"]}'));
-- Query temperature sensors only
SELECT
reading_id,
sensor_data:sensor_id::STRING as sensor_id,
sensor_data:temp::FLOAT as temperature,
sensor_data:unit::STRING as unit,
sensor_data:battery::INTEGER as battery_level
FROM sensor_readings
WHERE sensor_data:sensor_id LIKE 'T%';
Conclusion
The addition of Variant to Apache Parquet represents a significant milestone in the format’s evolution. By standardizing Variant as a logical type within Apache Parquet, the format now provides efficient storage for semi-structured data, enables meaningful statistics collection, and ensures cross-engine interoperability.
The well-documented specification has catalyzed broad ecosystem adoption, with multiple reference implementations now available across languages. This cross-language support ensures that Variant can be seamlessly integrated into diverse data processing environments, from analytical databases to streaming platforms, making it a universal solution for handling evolving schemas in modern data architectures.
Resources
- Apache Parquet Format Specification: https://github.com/apache/parquet-format
- Variant Type Specification: Variant Logical Type
- Variant Encoding Specification: Variant Binary Encoding
- Variant Shredding Specification: Variant Shredding
- Community Discussions: dev@parquet.apache.org
Native Geospatial Types in Apache Parquet
Geospatial data has become a core input for modern analytics across logistics, climate science, urban planning, mobility, and location intelligence. Yet for a long time, spatial data lived outside the mainstream analytics ecosystem. In primarily non-spatial data engineering workflows, spatial data was common but required workarounds to handle efficiently at scale. Formats such as Shapefile, GeoJSON, or proprietary spatial databases worked well for visualization and GIS workflows, but they did not integrate cleanly with large scale analytical engines.
The introduction of native geospatial types in Apache Parquet marks a major shift. Geometry and geography are no longer opaque blobs stored alongside tabular data. They are now first class citizens in the columnar storage layer that underpins modern data lakes and lakehouses.
This post explains why native geospatial support in Parquet matters and gives a technical overview of how these types are represented and stored.
Why Geospatial Types Matter in Analytical Storage
Spatial data storage presents unique challenges: a single geometry may represent a point, a road segment, or a complex polygon with thousands of vertices. Queries are also different: instead of simple equality or range filters, users ask spatial questions such as containment, intersection, distance, and proximity in two (XY) or even three (XYZ) dimensions.
Historically, geospatial columns in Parquet were stored as generic binary or string values, with spatial meaning encoded in external metadata. This approach had several limitations.
- Query engines could not detect a column was GEOMETRY or GEOGRAPHY without an explicit function call by the user (even if the engine supported GEOMETRY or GEOGRAPHY types natively)
- Query engines could not apply statistics-based pruning: full Parquet files were required to be read even for spatial queries that returned a small number of rows.
Native geospatial types address these issues directly. By making geometry and geography part of the Parquet logical type system, spatial columns become visible to query planners, execution engines, and storage optimizers.
A key benefit is the ability to attach spatial statistics such as bounding boxes to column chunks and row groups. With bounding boxes available in Parquet statistics, engines can skip entire row groups that fall completely outside a query window. This dramatically reduces IO for spatial filters and joins, especially on large datasets.
In practice, this means that spatial analytics can finally benefit from the same performance techniques that made Parquet dominant for non-spatial workloads.
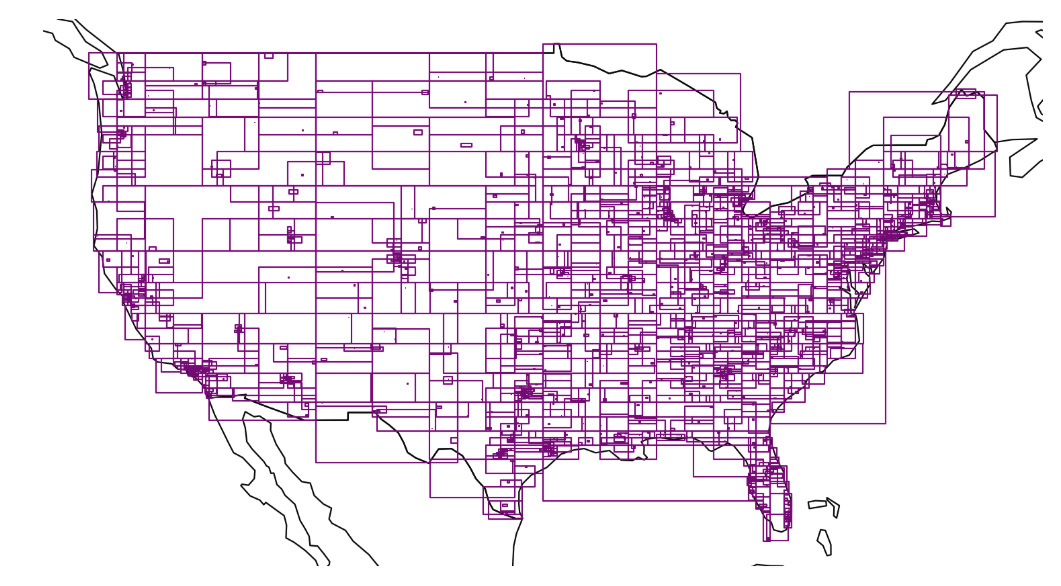
Figure 1: Visualization of bounding boxes for 130 million buildings stored in a Parquet file from the contiguous U.S. (Microsoft Buildings, file from geoarrow.org/data, visualization code here)
Consider a SedonaDB Spatial SQL query that filters buildings by intersection with a small region around Austin, Texas:
SELECT * FROM buildings
WHERE ST_Intersects(
geometry,
ST_SetSRID(
ST_GeomFromText('POLYGON((-97.8 30.2, -97.8 30.3, -97.7 30.3, -97.7 30.2, -97.8 30.2))'),
4326
)
)
With bounding box statistics attached to each row group, the query engine compares the query window against each row group’s bounding box before reading any geometry data. In the visualization below, the query window (red box) overlaps with only 3 row groups out of 2,585 (highlighted in orange). The engine skips all other row groups entirely.
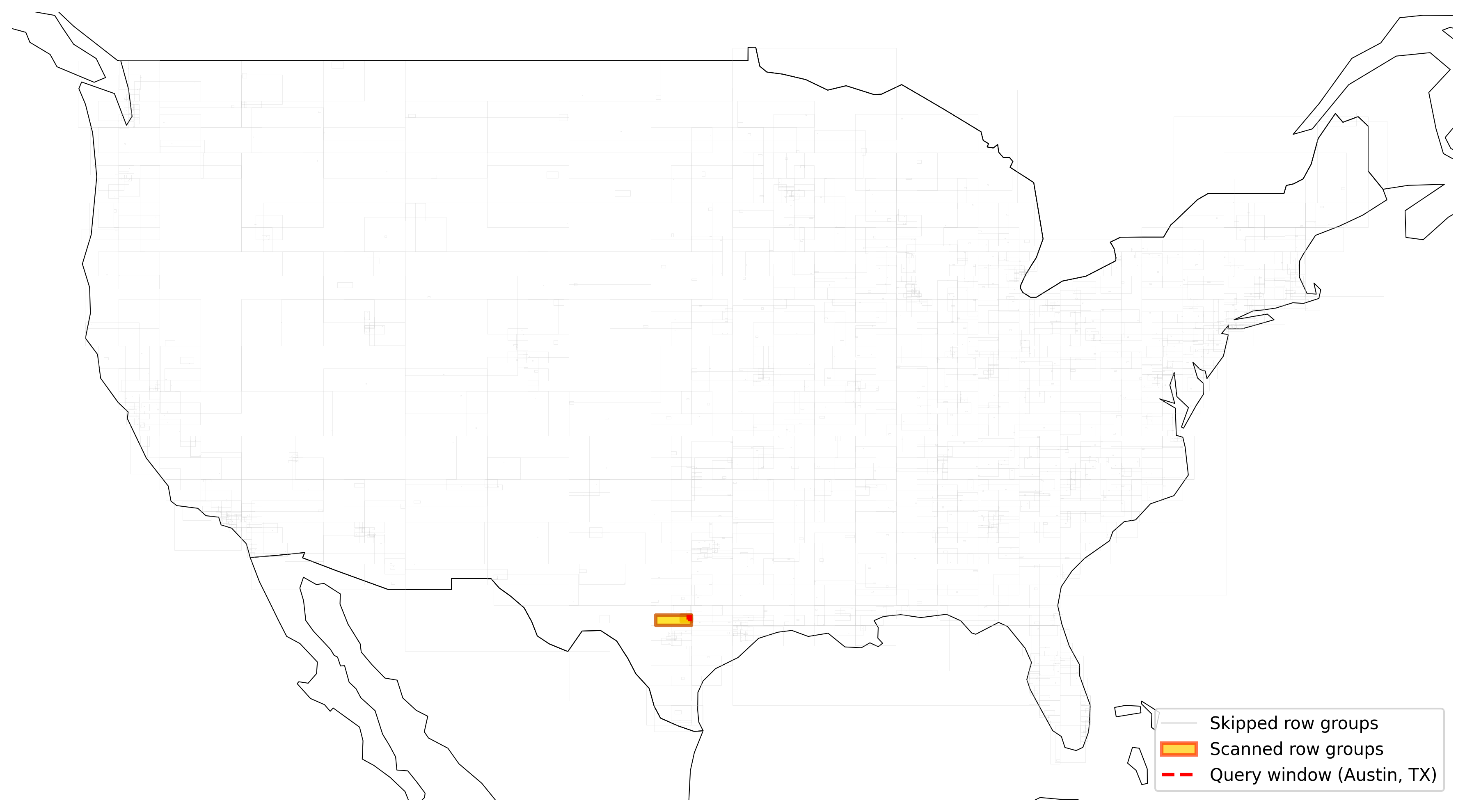
Figure 2: Spatial pruning in action: the query window over Austin (red) intersects only 3 row group bounding boxes (orange). The remaining 2,582 row groups (gray) are skipped without reading their data. (visualization code here)
From GeoParquet Metadata to Native Types
Before Parquet adopted GEOMETRY and GEOGRAPHY types in 2025, the GeoParquet community had already standardized how geometries should be stored in Parquet as early as 2022, using well known binary encoding plus a set of metadata keys. This was an important step because it enabled interoperability across tools.
However, geometry columns were still fundamentally binary columns with sidecar metadata. Engines had to explicitly opt in to understanding that metadata and its placement in the file key/value metadata made it difficult to integrate with primarily non-spatial engines that were not designed to be extended in this way. Moreover, data lake table formats such as Apache Iceberg require concrete, first class Parquet data types to enable engine interoperability, which sidecar metadata cannot adequately support.
The newer direction, sometimes referred to as GeoParquet 2.0, moves geospatial concepts directly into the Parquet type system. Geometry and geography are defined as logical types, similar in spirit to decimal or timestamp types. This eliminates ambiguity such that non-spatial engines are better able to integrate Geometry and Geography concepts, improving type fidelity and performance for spatial and non-spatial users alike.
Overview of Geospatial Types in Parquet
Parquet introduces two primary logical types for spatial data.
GEOMETRY
The GEOMETRY type represents planar spatial objects. This includes points, linestrings, polygons, and multi geometries. The logical type indicates that the column contains spatial objects, while the physical storage uses a standard binary encoding.
Typical examples include:
- Engineering or CAD data in local coordinates
- Projected map data such as Web Mercator or UTM
- Spatial joins and overlays where longitude and latitude data distributed over a small area or where vertices are closely spaced, such as intersections, unions, clipping, and containment analysis
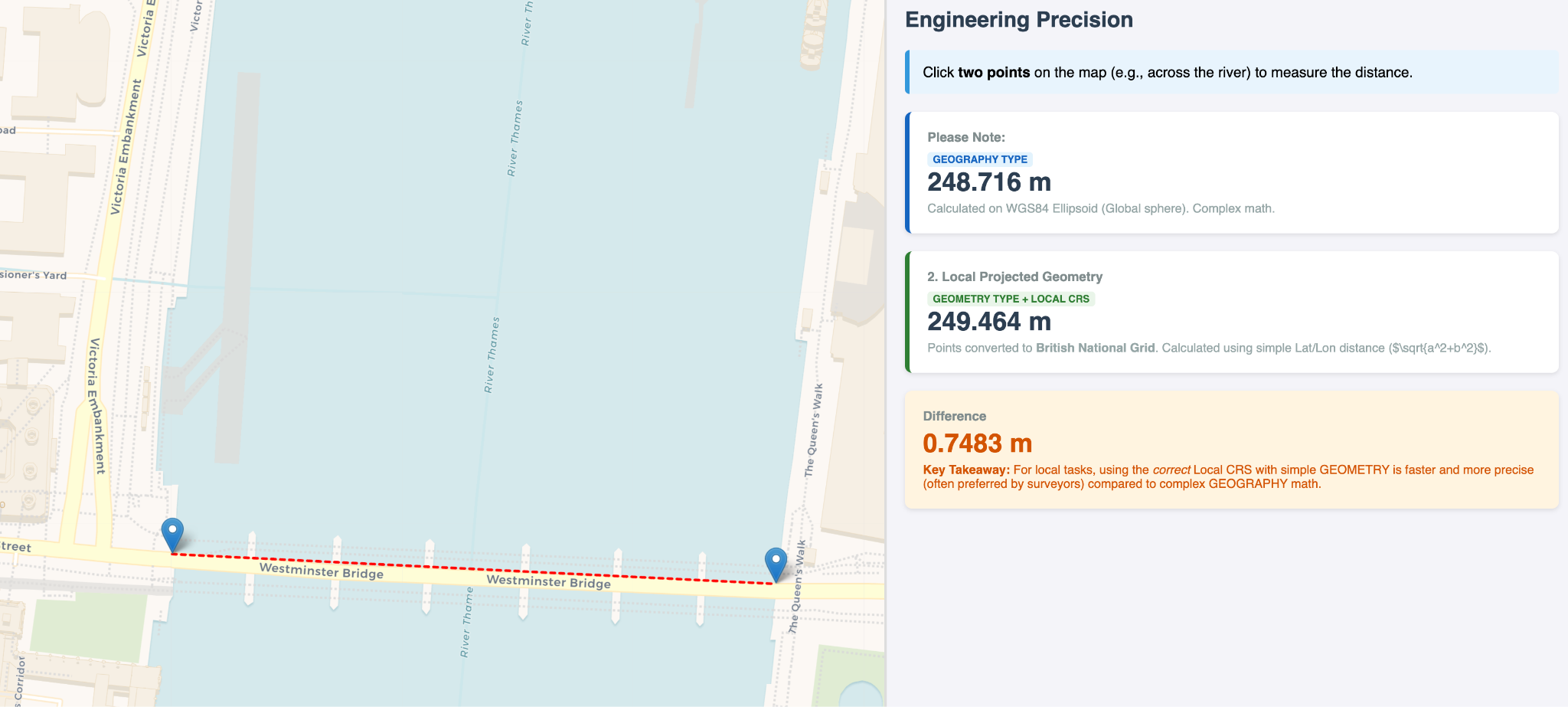
Figure 3: Building the London Westminster Bridge: the Geometry type under a local coordinate reference system would provide better precision and performance than the Geography type.
GEOGRAPHY
The GEOGRAPHY type is similar to GEOMETRY but represents objects on a spherical or ellipsoidal Earth model. Geography values are encoded using longitude and latitude coordinates expressed in degrees.
Common use cases include:
- Global scale datasets that span large geographic extents (e.g., country boundaries)
- Distance calculations where curvature of the earth matters (e.g., the distance between New York and Beijing)
- Use cases such as aviation, maritime tracking, or global mobility
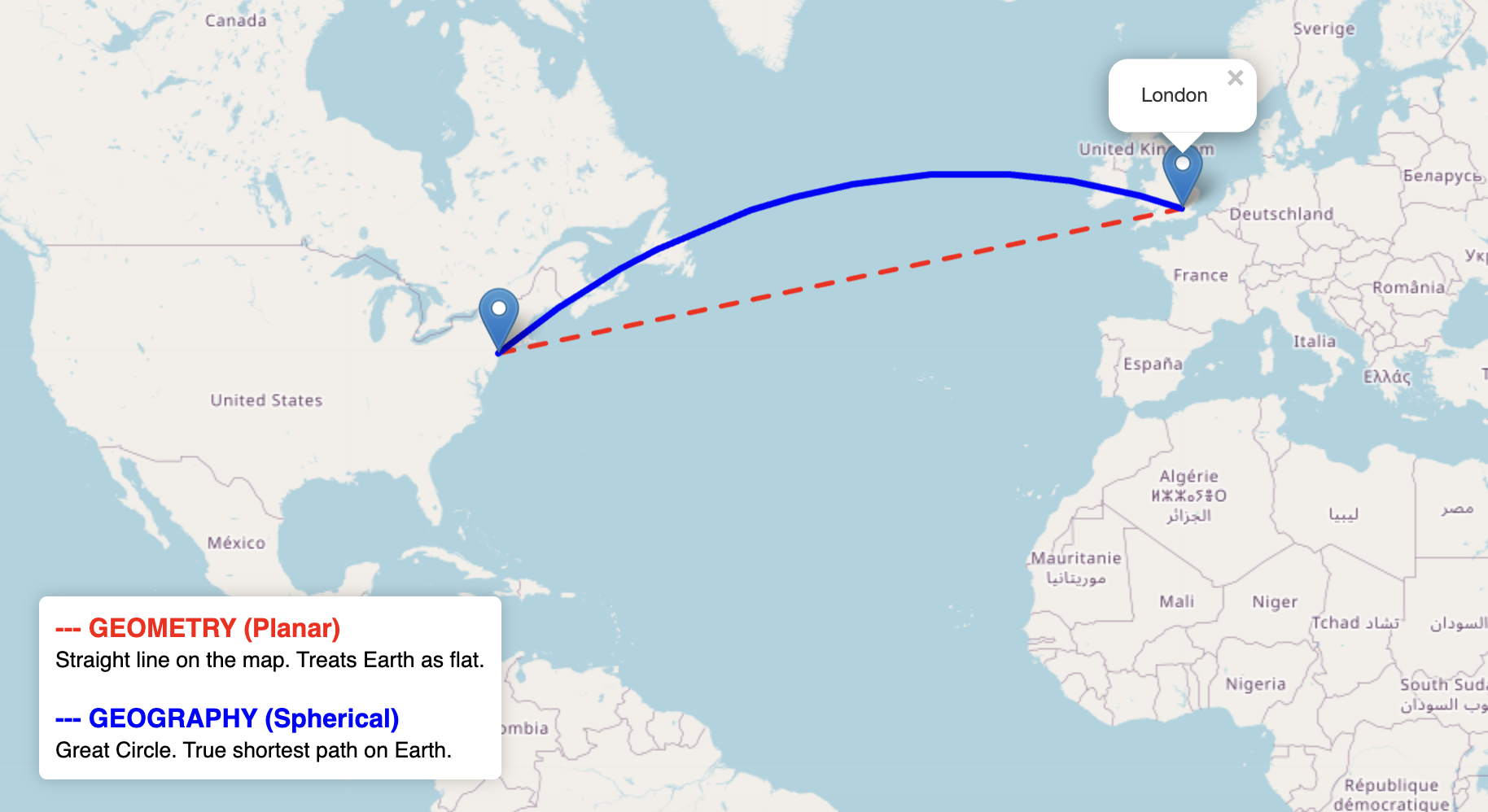
Figure 4: The shortest distance between London and NYC should cross Canada when using the Geography type, whereas the Geometry type incorrectly misses Canada.
Both types integrate into Parquet schemas just like other logical types. From the perspective of a schema definition, a geometry column is no longer an opaque binary field but a typed spatial column.
How Geospatial Types Are Stored
Although geospatial types are logical constructs, their physical storage follows Parquet’s existing columnar design. The following points highlight key aspects of the geospatial type design.
- Physical encoding Geometry and geography values are stored as binary payloads, using Well Known Binary (WKB) encoding. This ensures compatibility across engines and languages.
- Spatial statistics In addition to standard Parquet statistics such as null counts, spatial columns can carry bounding box information. Each row group can record the minimum and maximum extents of the geometries it contains. Query engines can use this information to prune data early when evaluating spatial predicates.
- Engine interoperability Because the spatial meaning is encoded as a Parquet logical type, engines do not need out of band conventions to interpret the column. A reader that understands Parquet geospatial types can immediately treat the column as a spatial object.
- Coordinate Reference System (CRS) information CRS information is stored in the file metadata (i.e., type definition) using authoritative identifiers or structured definitions such as EPSG codes or PROJJSON strings.
Native geospatial types align naturally with modern lakehouse architectures built on Parquet. Table formats such as Apache Iceberg no longer need to reinvent geospatial logic since core spatial semantics live in Parquet. Instead, they can focus on well defined type mappings between Parquet and Iceberg and on propagating spatial statistics into the tables.
Implementation status and ecosystem adoption
Native Parquet geo types are not theoretical. Geometry and geography have already been implemented across multiple core libraries, indicating broad and growing adoption.
Today, support exists in multiple languages and runtimes, including Parquet Java, Arrow C++, Rust, Hyparquet Javascript, DuckDB, and more! This ensures that geospatial Parquet files can be produced and consumed consistently across ecosystems, from JVM engines to native and embedded query engines.
An up to date view of implementation coverage can be found in the official Parquet documentation.
Conclusion
Native geospatial support in Apache Parquet represents a foundational improvement for spatial analytics and a welcome quality of life improvement for general-purpose workloads with a spatial component. By elevating geometry and geography to first class logical types, Parquet enables efficient storage, meaningful statistics, and true engine interoperability.
Bounding boxes, columnar layout, and standard encodings together allow spatial data to participate fully in modern analytics systems. As a result, geospatial workloads no longer need specialized storage formats or isolated systems. They can live natively inside the open, scalable data lake ecosystem.
To get started with Geometry/Geography in Parquet, see the example files provided by the geoarrow-data repository or write your own using your favourite Parquet implementation!
import geoarrow.pyarrow as ga # For GeoArrow extension type registration
import geopandas
import pyarrow as pa
from pyarrow import parquet
# From GeoPandas, create a GeoDataFrame from your favourite data source
url = "https://raw.githubusercontent.com/geoarrow/geoarrow-data/v0.2.0/natural-earth/files/natural-earth_countries.fgb"
df = geopandas.read_file(url)
# Write to Parquet using pyarrow.parquet()
tab = pa.table(df.to_arrow())
parquet.write_table(tab, "countries.parquet")
# Verify that the Geometry logical type was written to the file
parquet.ParquetFile("countries.parquet").schema
#> <pyarrow._parquet.ParquetSchema object at 0x10776dac0>
#> required group field_id=-1 schema {
#> optional binary field_id=-1 name (String);
#> optional binary field_id=-1 continent (String);
#> optional binary field_id=-1 geometry (Geometry(crs=));
#> }
# Geometry is read to a pyarrow.Table as GeoArrow arrays that can be
# converted back to GeoPandas
tab = parquet.read_table("countries.parquet")
df = geopandas.GeoDataFrame.from_arrow(tab)
df.head(2)
#> name continent \
#> 0 Fiji Oceania
#> 1 United Republic of Tanzania Africa
#>
#> geometry
#> 0 MULTIPOLYGON (((180 -16.06713, 180 -16.55522, ...
#> 1 MULTIPOLYGON (((33.90371 -0.95, 34.07262 -1.05...
Parquet Format Releases
2.12.0
The latest version of parquet-format is 2.12.0.
To check the validity of this release, use its:
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
2.11.0
The latest version of parquet-format is 2.11.0.
To check the validity of this release, use its:
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
2.10.0
The latest version of parquet-format is 2.10.0.
To check the validity of this release, use its:
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
2.9.0
The latest version of parquet-format is 2.9.0.
To check the validity of this release, use its:
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
2.8.0
The latest version of parquet-format is 2.8.0.
To check the validity of this release, use its:
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
2.7.0
The latest version of parquet-format is 2.7.0.
To check the validity of this release, use its:
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
Parquet-Java Releases
1.17.0
The latest version of parquet-java is 1.17.0.
For the changes, please check out the Release on Github.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.16.0.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.17.0</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.16.0
The latest version of parquet-java is 1.16.0.
For the changes, please check out the Release on Github.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.15.2.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.16.0</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.15.2
The latest version of parquet-java is 1.15.2.
For the changes, please check out the Release on Github.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.14.4.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.2</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.15.1
The latest version of parquet-java is 1.15.1.
For the changes, please check out the Release on Github.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.14.4.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.1</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.15.0
The latest version of parquet-java is 1.15.0.
For the changes, please check out the Release on Github.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.15.0.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.0</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.14.4
The latest version of parquet-java is 1.14.4.
With the following bugfixes:
- GH-3040: DictionaryFilter.canDrop may return false positive result when dict size exceeds 8k
- GH-3029: Fix EncryptionPropertiesHelper not to use
java.nio.file.Path - GH-3042: Throw exception in BytesInput
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.13.1.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.4</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.14.3
The latest version of parquet-java is 1.14.3.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.13.1.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.3</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.14.2
The latest version of parquet-java is 1.14.2.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.13.1.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.2</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.14.1
The latest version of parquet-java is 1.14.1.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.13.1.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.1</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.14.0
The latest version of parquet-java is 1.14.0.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.13.1.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.0</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.13.1
The latest version of parquet-java is 1.13.1.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.12.3.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.13.1</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.13.0
The latest version of parquet-java is 1.13.0.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.12.3.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.13.0</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.12.3
The latest version of parquet-java is 1.12.3.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.11.2.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.12.3</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/
1.12.2
The latest version of parquet-java is 1.12.2.
To check the validity of this release, use its:
The latest version of parquet-java on the previous minor branch is 1.11.2.
To check the validity of this release, use its:
Downloading from the Maven central repository
The Parquet team publishes its releases to Maven Central.
Add the following dependency section to your pom.xml:
<dependencies>
...
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.12.2</version> <!-- or latest version -->
</dependency>
...
</dependencies>
Older Releases
Older releases can be found in the Archives of the Apache Software Foundation: https://archive.apache.org/dist/parquet/